
Feb 8, 2022
Both offer data-labeling services. One is centralized. One is not. But what are the differences between the two; what is the benefit of using a decentralized service over a Web 2.0 one?
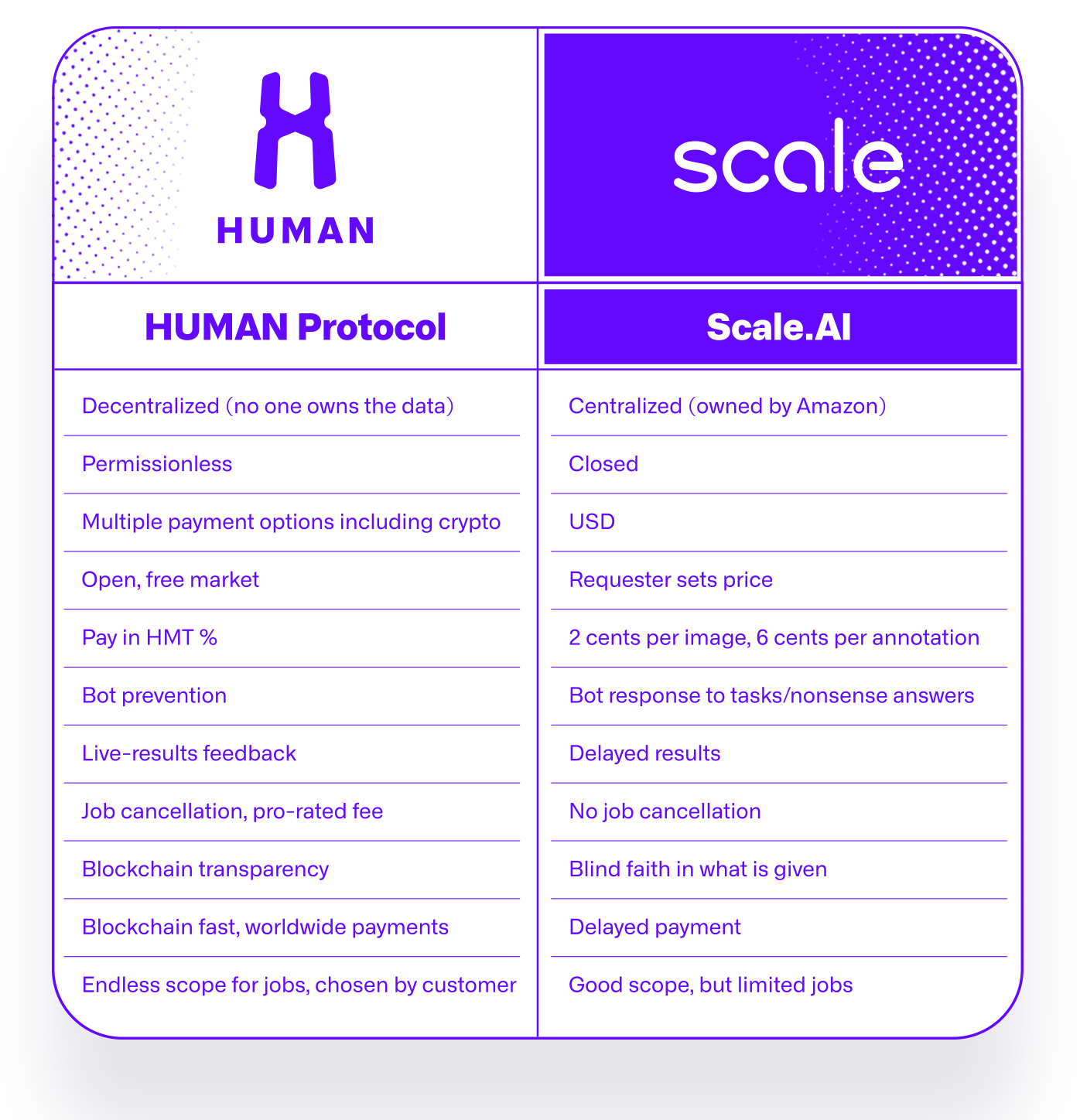
In reality, we are comparing the benefits, but it is not an either-or situation. HUMAN Protocol is not built only as a competitor to work services like Scale AI and MTurk. It is also built to complement them. Because HUMAN is the infrastructure to automate digital job markets, work services can loop-in their existing work pools, and benefit from access to new kinds of tools and services, automation, and payment on-chain.
HUMAN Protocol also uses a lowest-cost algorithm to ensure that the Requester always gets the highest quality for the lowest price available; if Scale AI and MTurk are both on HUMAN Protocol, and one is 20% cheaper than the other, HUMAN will automatically funnel work to that service. With an eye always on quality, HUMAN intelligently arbitrates between services to ensure the best price for work is achieved.
More work pools. More transactions. More options for everyone.
Scale AI is a Web 2.0 data-labeling service. In practice, this means that a machine learning practitioner – a startup, a scientist, or a large corporation – can engage Scale AI to fulfill the labeling of images to feed ML algorithms. Scale AI is an impressive company, with many potential benefits. That said, it’s built on limited infrastructure, and inherits some of those limitations.
These limitations can largely fit three categories:
Centralization has a strand of problems which result in limitations of perspective.
By not including everyone and anyone, a company can limit the potential of its markets; open markets are better markets, and data markets are no different.
Centralized entities limit:
Together, these limitations have an effect on the quality of work; and, even if the work is of a high quality from Scale AI, there is something to be said about the benefits of inclusivity when it comes to data-labeling services. If this work creates the foundation for future AI, we want a meritocracy; the very best scientists and startups to access these services, to determine themselves what data they want labeled, and who should label it. It would be unwise to leave such things in the hands of the few, when it comes to a technology that will affect so many.
Then there is the Web 2.0 strand of problems, which are more systematic failures. These are pragmatic issues resulting from the archaic structures around which Web 2.0 services are built:
Structurally, Web 2.0 can not do much to change these things quickly. The benefit of HUMAN is, in a word, one of streamlining; from automation, to a functionality of pausing and cancelling jobs, to lower costs, and a pay-for-what-you-get model.
Finally, we must look at the problems facing the advancement of generalized AI, which has been twenty years away for the last sixty years.
To realize the future of generalized AI, we require vast inputs from vast sources, both those on the side of the scientists who invent and create technologies, and on the side of those who respond. Limited responses provide limited data, and limited AI products that cannot provide the flexibility and diversity required to create granular datasets for the future of AI. HUMAN Protocol is built for now – it already hosts useful labeling applications. It is, more importantly, built for the future; by our commitment to open-sourcing all our technology, HUMAN Protocol’s current applications can be seen as a blueprint of further integrations. Without a central authority determining what data can be created, HUMAN is a flexible, responsive solution to the naturally evolving demands of the AI world.
For the latest updates on HUMAN Protocol, follow us on Twitter or join our Discord. Alternatively, to enquire about integrations, usage, or to learn more about HUMAN Protocol, get in contact with the HUMAN team.
Legal Disclaimer
The HUMAN Protocol Foundation makes no representation, warranty, or undertaking, express or implied, as to the accuracy, reliability, completeness, or reasonableness of the information contained here. Any assumptions, opinions, and estimations expressed constitute the HUMAN Protocol Foundation’s judgment as of the time of publishing and are subject to change without notice. Any projection contained within the information presented here is based on a number of assumptions, and there can be no guarantee that any projected outcomes will be achieved.

